DSpark: Speculative decoding accelerates LLM inference [pdf] LLM inference speed is an important technical consideration for copilots, agents, and shared AI workspaces. Latency can
LLM inference speed is an important technical consideration for copilots, agents, and shared AI workspaces. Latency can affect whether a system feels responsive in day-to-day use. Based on the analyzed sources, DSpark: Speculative decoding accelerates LLM inference [pdf] sits within a broader effort to make decoding faster while preserving output behavior. That is relevant to AI offices like Nonilion, where humans and AI agents may work together across meeting follow-ups, async coordination, and workflow automation.
01DSpark: Speculative decoding accelerates LLM inference [pdf] — what the paper is addressing
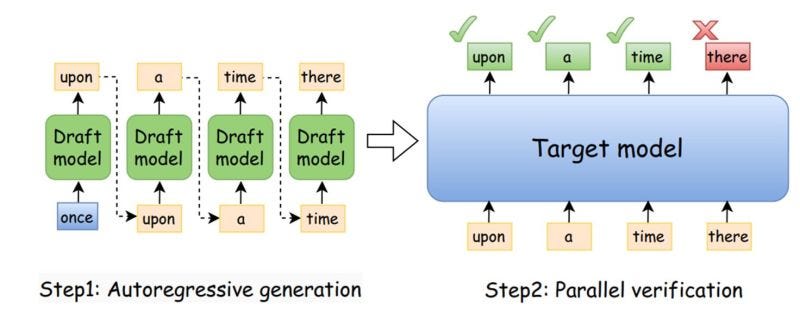
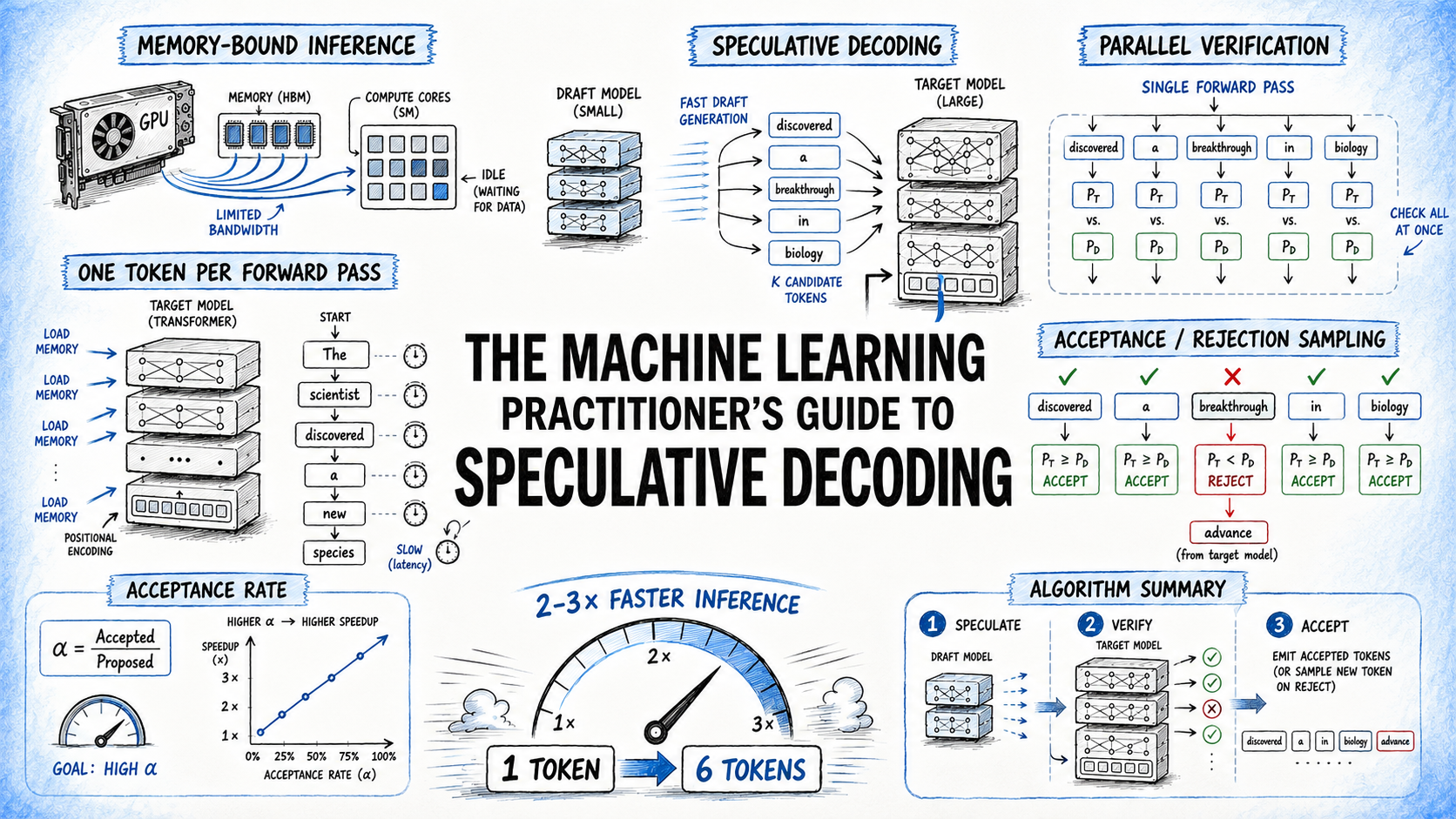
The core issue is that LLM inference can be constrained by sequential token generation. The sources describe speculative decoding as a way to propose multiple tokens with a draft model and then verify them with the target model, which can reduce the number of target forward passes needed.
Want your team to run this workflow with AI-native execution?
The DSpark-related source describes DSpark as a speculative decoding framework associated with DeepSeek V4 and presents it as an engineering-focused update rather than a new model architecture. It also references an open-sourced speculative decoding system called DeepSpec. Taken together, the sources point to a practical direction: inference acceleration is increasingly treated as a systems and deployment concern.
02What speculative decoding is, and why LLM inference speed matters
Speculative decoding is described in the sources as a method that accelerates LLM inference by reducing the number of forward passes. The general idea is to let a drafter propose candidate tokens and then verify them with the target model. If the verification succeeds, the system can advance more efficiently than standard token-by-token decoding.
Why does this matter? Because sequential decoding introduces latency at every step. For product teams, that can affect chat response time, agent throughput, and the experience of waiting for an AI-generated follow-up.
For a Nonilion-style AI office, that is a practical concern. Faster inference can support meeting summaries, async task completion, and other collaborative workflows where responsiveness matters.
03How DSpark fits into the broader family of speculative decoding methods
The analyzed sources place DSpark alongside other speculative decoding methods that aim to improve inference efficiency while preserving output behavior. One source discusses speculative decoding as generating multiple tokens with a single target forward pass. Another focuses on lossless speculative decoding for heterogeneous vocabularies, where the drafter model does not share the same vocabulary as the target model.
That vocabulary detail shows that the field includes more than one implementation path. DSpark appears to belong to a practical engineering direction in which speculative decoding is packaged for real systems.
In that sense, DSpark can be understood as part of a broader trend: make generation faster, preserve correctness, and reduce the operational cost of serving LLMs.
04Why lossless speedups matter: latency, verification overhead, and production tradeoffs
The phrase lossless acceleration is important. The sources emphasize that these methods are intended to speed up inference without changing the final output. That is especially useful in production, where teams care about correctness, trust, and consistency.
At the same time, speculative decoding introduces verification overhead. The system must check proposed tokens against the target model. So the tradeoff is not “free speed,” but a balance between extra draft work and fewer expensive target passes.
This is why lossless methods are attractive for production AI systems:
They preserve output behavior.
They can reduce latency.
They are easier to justify in workflows where accuracy matters.
They fit systems that need dependable agent execution.
For AI offices, that means faster models are most useful when they still behave predictably in shared workspaces, meeting follow-ups, and internal coordination flows.
05Where DSpark differs from lookahead decoding and other adjacent acceleration approaches
One of the competitor sources references lookahead decoding and notes that it differs from other methods because it is designed for accelerating LLM decoding while not changing the output. Based on the analyzed sources, the broader comparison point is that multiple decoding acceleration approaches are converging on the same business need: lower latency without sacrificing correctness.
DSpark, as described in the sources, is positioned as a speculative decoding framework added to an existing model stack. That makes it feel more like a deployment-oriented implementation than a new decoding philosophy.
The practical distinction for teams is this:
Some methods focus on algorithmic changes to decoding.
Some focus on compatibility between drafter and target vocabularies.
Some focus on system-level integration and engineering implementation.
When choosing between them, teams should care less about naming and more about whether the method fits their model stack, latency target, and production constraints.
06When teams should care: the practical checklist for copilots, agents, and internal AI systems
Teams should care about speculative decoding when LLM latency affects user experience or throughput. That includes copilots, agentic workflows, internal knowledge assistants, and shared AI office systems.
A practical checklist based on the sources:
Is inference latency visible to users?
Does the workflow depend on repeated generation?
Is output correctness non-negotiable?
Can the system afford verification overhead?
Does the model stack support the chosen decoding method?
If the answer to most of these is yes, speculative decoding becomes strategically relevant.
For Nonilion, this is especially relevant in workflows where AI agents help coordinate work across people: drafting follow-ups, organizing async handoffs, and supporting shared workspaces where speed and reliability both matter.
07What this means for AI offices like Nonilion: faster inference in shared workspaces, meeting follow-ups, and async coordination
In an AI office, latency can affect how people use shared assistants. If a system responds quickly, it may be easier to keep it in the flow of work. If it lags, people may return to manual coordination.
That is why speculative decoding matters for this platform as a practical example of human + AI collaboration. Faster inference can support:
meeting follow-ups that arrive while the discussion is still fresh,
async coordination where agents prepare drafts or summaries between team updates,
shared workspaces where multiple people rely on the same AI system,
workflow automation where delays can add up across tasks.
The sources do not claim these exact office outcomes, but they do support the underlying logic: reducing inference latency can make AI systems more usable in collaborative settings.
08How lower latency changes human + AI collaboration in agentic workflows
Lower latency does more than improve speed metrics. It can change how humans and AI agents divide labor.
When inference is faster, humans may delegate smaller tasks more naturally. They can ask for a draft, review it, refine it, and continue. Agents can execute steps in sequence without becoming a bottleneck. That can make the collaboration feel less like batch processing and more like a live workspace.
In a this platform-style environment, this can support:
quicker back-and-forth between humans and agents,
more continuous async execution,
tighter coordination across team tasks,
better responsiveness in shared decision-making.
So speculative decoding is not only about model efficiency. It is also about making human + AI collaboration feel immediate enough to support everyday work.
09Deployment considerations: model compatibility, engineering complexity, and workflow design
The sources point to an important deployment reality: these methods are not only about theory. They involve engineering implementation and compatibility choices.
Key considerations include:
Model compatibility: Some methods assume specific relationships between drafter and target models, while others address heterogeneous vocabularies.
Engineering complexity: A framework like DSpark suggests integration work, not just a model swap.
Workflow design: Faster inference only helps if the product flow actually benefits from lower latency.
This is why speculative decoding should be evaluated as part of system design. The best method is the one that fits the product, the model stack, and the collaboration pattern.
10A practical lens: using DSpark-style inference optimization in a this platform-style AI office
A this platform-style AI office would treat DSpark-like optimization as infrastructure for collaboration, not as a standalone feature.
That means asking questions such as:
Which workflows are latency-sensitive?
Which agent tasks need fast verification?
Where does a slight delay break the rhythm of teamwork?
Which internal automations would benefit from lossless acceleration?
In practice, this lens helps teams connect technical optimization to daily work. The value is not only faster tokens. The value is smoother coordination between humans and AI agents in a shared workspace.
11Conclusion: why speculative decoding is becoming a product decision, not just a research topic
Based on the analyzed sources, DSpark: Speculative decoding accelerates LLM inference [pdf] belongs to a broader shift toward lossless acceleration of LLM inference. Speculative decoding is increasingly relevant because teams want lower latency without sacrificing output quality.
That makes it a product decision. It affects user experience, agent throughput, and the design of collaborative AI systems. For this platform, the practical takeaway is straightforward: faster inference can make shared workspaces, meeting follow-ups, and async coordination feel more natural, which can strengthen human + AI collaboration.
12Why This Trend Matters for Nonilion
This trend matters to Nonilion because it points to a bigger change: teams are moving from simple calls toward persistent, AI-supported collaboration spaces. Nonilion can bridge live presence, meeting context, avatars, and follow-up work so the trend becomes a usable workflow instead of a headline.
13Shareable Extracts
The trend is not just "DSpark: Speculative decoding accelerates LLM inference [pdf]" - it is a signal that team coordination is becoming the next competitive edge.
Hot take: the teams that win from this shift will not be the ones with more meetings; they will be the ones with clearer shared context after every meeting.
If dspark: speculative decoding accelerates llm inference [pdf] keeps moving this fast, remote teams need a workspace where conversation, presence, and follow-up stay connected.
DSpark: Speculative decoding accelerates LLM inference [pdf] LLM inference speed is an important technical consideration for copilots, agents, and shared AI workspaces.
Based on the analyzed sources, DSpark: Speculative decoding accelerates LLM inference [pdf] sits within a broader effort to make decoding faster while preserving output behavior.
14Social Hooks
Everyone is talking about DSpark: Speculative decoding accelerates LLM inference [pdf]. The overlooked part is what happens to team workflows after the headline fades.
The uncomfortable question behind DSpark: Speculative decoding accelerates LLM inference [pdf]: are teams adapting their collaboration systems fast enough?
This is not a meeting trend. It is a coordination trend, and products like Nonilion sit right in the middle of that shift.
This article on DSpark: Speculative decoding accelerates LLM inference [pdf] was generated by the Nonilion AI blog workflow using web research inputs and AI-assisted synthesis.









![DSpark: Speculative decoding accelerates LLM inference [pdf]](https://dyfemgew43vetjj3.public.blob.vercel-storage.com/blog/source/dspark-speculative-decoding-accelerates-llm-inference-pdf-1782570692602-e8Lde47QNHBVLWliC0iJY3XwYNvbEw.png)